Research
|
|
Research and Interests |
|
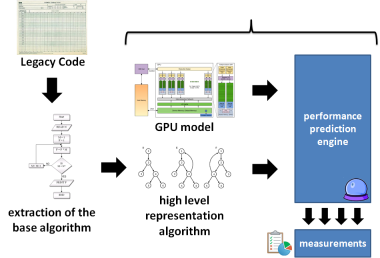
In recent years, the development of HPC (High Performance Computing) applications have evolved to take advantage of the use of accelerator devices. Right now, the top ten equipment from the TOP 500 rank are equipped with some kind of accelerator, especially GPUs (Graphic Processing Units) or MICs (Many Integrated Core). In fact, the TOP 500 rank has been headed by equipment compound by processing nodes with hybrid hardware architectures, using a CPU and an accelerator at the same time. However, the development of applications for this kind of machinery tends to be complex and costly. The main reason for this is the fact that it demands usage of hybrid programming techniques, in order to extract all parallelism from the hardware. Programming frameworks as such OpenMP, MPI, LibNUMA, PThreads, and more recently CUDA (Compute Unified Device Architecture) and OpenCL are commonly mixed together to create combined applications that are adherent to these hybrid hardware architectures. Nevertheless, the differences between the architectures of CPUs and accelerators are significant. While a CPU must be flexible to process any kind of application, a GPU or MIC is designed to run applications that are based on massive parallel data processing. This way, building applications for accelerator devices requires a new development approach.  Taking into account the amount of existing legacy scientific applications, these architectural differences may become a setback. For example, when talking about migration of legacy applications to GPU, especially those created with third generation programming languages, such as C or FORTRAN, it is mandatory to review the application architecture and identify where to perform design and architecture changes to harness the massive parallel power of the GPU. Considering the differences between sequential and parallel programming models, the migration process will demand a thorough analysis of the original application in order to find opportunities for parallelization and performance enhancements, and only after then to create the migration road map. On this basis, the ability to predict how an application will behave when executed on a specific hardware architecture may represent a valuable tool to support the migration process of a legacy application to GPU. For example, if would be possible to test different approaches about how to implement a data structure accordingly to CUDA constraints during (or prior to) the coding process to be executed, certainly a better performance would be achieved. However, most of the existing studies that are focused on performance prediction are based on the code analysis at run time, which means that the CUDA or OpenCL source code must have been created previously. On this basis, my research interests lie in:
|
|
 |
 |
| Projects | Writing |
| Projects | |||
|---|---|---|---|
| Project | Description | ||
Sagan Simulator
|
SaganSimulator is a gravitational simulator created in C and CUDA C language.
It is compound by three code versions: a pure "sequential" C version; a global
memory based CUDA version and a shared memory based CUDA version.There is also
the SSView module, created in OpenGL to create images and videos from the
numeric simulations. The project's name is a tribute to one of the greatest promoters of science, Dr. Carl Sagan. This project has the collaboration of:
|
||
| Channel on YouTube |
Repository on Google Code |
Technical Report |
|
|
|
|||
| Writing | ||
|---|---|---|
| Title | Description | Link |
| Desenvolvendo aplicações de uso geral para GPU com CUDA | ||
| Mini-curso apresentado na Escola Regional de Informática 2014, em 16 de Setembro de 2014 na Universidade de Santa Cruz do Sul - UNISC. | ||
|
Lecture presented at Escola Regional de Informática 2014, on 2014 September 16 at Universidade de Santa Cruz do Sul - UNISC.
Title: Developing General Purpose Applications for GPU using CUDA. |
||
| GPU Programming with CUDA A brief overview |
||
| In this paper we describe the architecture of a NVIDIA GPU, as well as the CUDA programming model. The basic statements are explained. We also provide an example of CUDA code, explaining its execution workflow in a GPU device. Text in English. |
|
|
| A Brief Overview of a Parallel Nbody Code | ||
| Exploration of Parallelism using OpenMP and MPI in a Cluster Matrix Multiplication Study Case | This technical report shows the results of our exploration of two levels of parallelism for a matrix multiplication applicaton running in a cluster environment. We used C + OpenMP + MPI to develop a small set of applications in order to explore different features of the tested hardware. Text in Brazilian Portuguese. |
|
| GPU Performance Prediction Using High-level Application Models | ||
| This was a speech presented on the ERAD RS 2014. This work intend to predict the performance of high-level represented algorithms when "running" on a GPU model. | ||
| Parallelization Strategies for NBody Codes on Multicore Architectures | ||
| Poster presented showing the results of our research regarding the development of better techniques for parallelization of nbody codes on multicore hardware architectures during the Symposium Humboldt Kolleg 2014, "Science and Method: Paradigms and perspectives" in Porto Alegre, RS, Brazil. | ||
|
|
||